

บริบทของปัญญาประดิษฐ์เชิงรู้สร้างและจุดกำเนิดของ Retrieval-Augmented Generation
การพัฒนาอย่างก้าวกระโดดของเทคโนโลยีปัญญาประดิษฐ์เชิงรู้สร้าง (Generative Artificial Intelligence) และโมเดลภาษาขนาดใหญ่ (Large Language Models หรือ LLMs) ได้พลิกโฉมวิธีการปฏิสัมพันธ์ระหว่างมนุษย์และระบบคอมพิวเตอร์อย่างสิ้นเชิง โมเดลเหล่านี้ซึ่งได้รับการฝึกสอนด้วยพารามิเตอร์นับพันล้านตัวและชุดข้อมูลขนาดมหึมา มีความสามารถอันโดดเด่นในการทำความเข้าใจภาษาธรรมชาติ การสรุปความ และการสร้างสรรค์ข้อความใหม่ อย่างไรก็ตาม โครงสร้างพื้นฐานของโครงข่ายประสาทเทียมที่อยู่เบื้องหลัง LLMs กลับซ่อนข้อจำกัดที่สำคัญระดับโครงสร้างเอาไว้ ประการแรกคือข้อจำกัดด้านขอบเขตของเวลาหรือที่เรียกว่าอุปสรรคจากการตัดขาดความรู้ (Knowledge Cutoff) ซึ่งทำให้โมเดลไม่สามารถรับรู้เหตุการณ์หรือข้อมูลที่เกิดขึ้นหลังจากสิ้นสุดกระบวนการฝึกสอนได้ ประการที่สองคือแนวโน้มในการสร้างข้อมูลเท็จหรืออาการประสาทหลอนของปัญญาประดิษฐ์ (AI Hallucination) ซึ่งเกิดขึ้นเมื่อโมเดลพยายามสร้างคำตอบด้วยความมั่นใจแม้จะขาดข้อมูลเชิงประจักษ์มารองรับ และประการสุดท้ายคือการขาดความสามารถในการเข้าถึงฐานข้อมูลเฉพาะทางหรือข้อมูลภายในระดับองค์กรที่มีความละเอียดอ่อนและไม่เคยถูกเปิดเผยสู่สาธารณะ 1
เพื่อก้าวข้ามข้อจำกัดเชิงโครงสร้างเหล่านี้ สถาปัตยกรรมที่เรียกว่า Retrieval-Augmented Generation (RAG) จึงได้ถูกนำเสนอและกลายเป็นกรอบการทำงานมาตรฐานระดับอุตสาหกรรมในเวลาอันรวดเร็ว RAG คือกรอบการทำงานทางปัญญาประดิษฐ์ที่ผสมผสานจุดแข็งของระบบสืบค้นข้อมูลแบบดั้งเดิม (Information Retrieval Systems) ซึ่งมีความแม่นยำสูง เข้ากับขีดความสามารถด้านความเข้าใจและสร้างสรรค์ภาษาของ LLMs 1 สถาปัตยกรรมนี้เปรียบเสมือนการเปลี่ยนรูปแบบการตอบคำถามของโมเดลจากการพึ่งพาเพียงความจำที่ถูกเข้ารหัสไว้ในน้ำหนักของพารามิเตอร์ (Parameterized Knowledge) ไปสู่การทำข้อสอบแบบเปิดหนังสือ (Open-book exam) ที่โมเดลสามารถดึงข้อมูลที่สดใหม่ แม่นยำ และเกี่ยวข้องที่สุดจากแหล่งข้อมูลภายนอกมาใช้เป็นบริบทประกอบการตัดสินใจก่อนที่จะสร้างคำตอบ 6 กลไกนี้ช่วยให้องค์กรสามารถควบคุมผลลัพธ์ของโมเดลภาษาได้อย่างเบ็ดเสร็จ ลดความเสี่ยงจากการสร้างข้อความที่เป็นเท็จ และสร้างความโปร่งใสผ่านการอ้างอิงแหล่งที่มาของข้อมูลได้อย่างชัดเจนโดยไม่ต้องลงทุนในกระบวนการฝึกสอนโมเดลใหม่ที่มีมูลค่ามหาศาล 2
สถาปัตยกรรมเชิงลึกและกลไกการทำงานของท่อส่งข้อมูล RAG
กระบวนการทำงานของระบบ RAG มาตรฐานได้รับการออกแบบมาเพื่อเสริมสร้างคุณภาพและความเป็นประโยชน์ของผลลัพธ์ผ่านวงจรการทำงานแบบบูรณาการ 5 ขั้นตอนหลัก ซึ่งประกอบด้วย การรับคำสั่งจากผู้ใช้งาน (Prompting) การดึงข้อมูลจากฐานความรู้ (Retrieving) การส่งคืนข้อมูลที่เกี่ยวข้อง (Returning) การเสริมบริบทลงในคำสั่ง (Augmenting) และการสร้างผลลัพธ์ขั้นสุดท้าย (Generating) 2 วงจรการทำงานนี้สามารถแบ่งออกเป็นระยะทางวิศวกรรมหลักได้สามระยะ ซึ่งแต่ละระยะมีความซับซ้อนและใช้เทคโนโลยีเฉพาะทางในการบริหารจัดการ
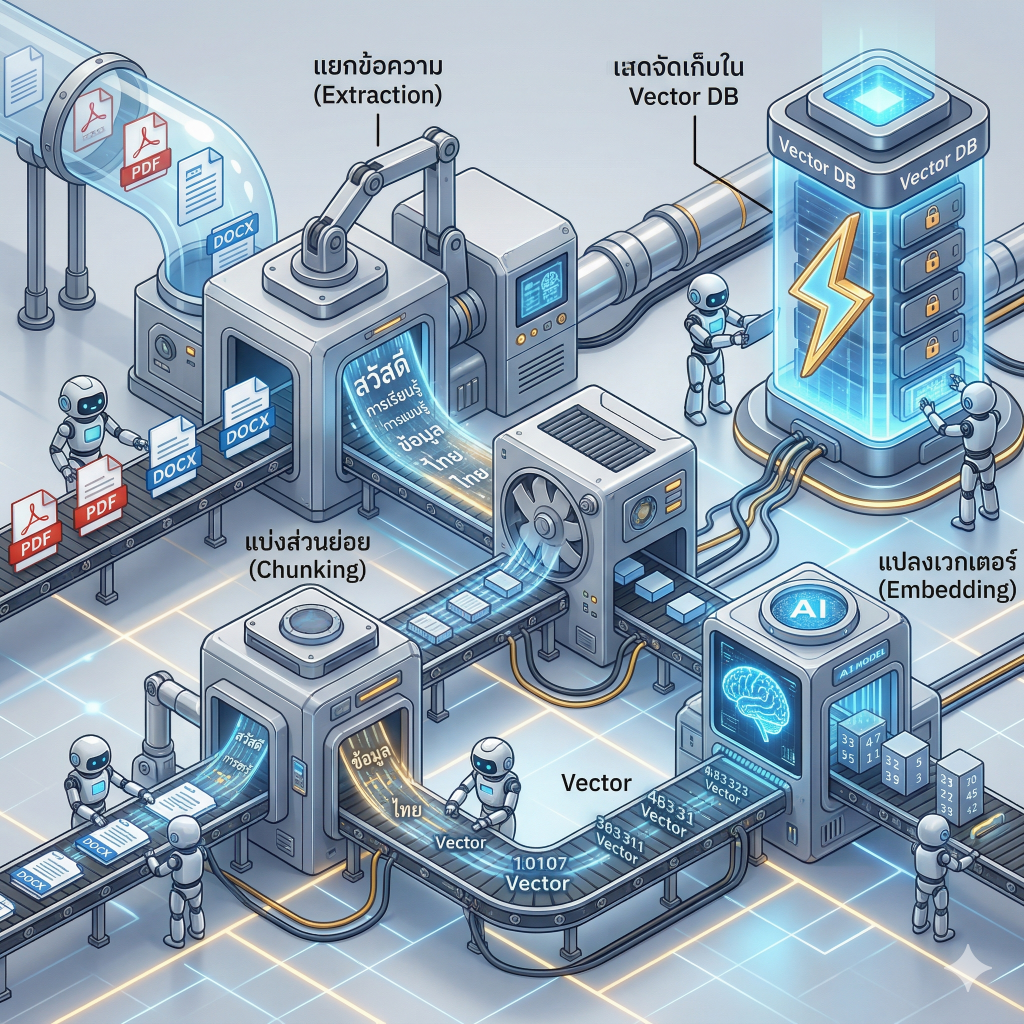
ระยะการนำเข้าข้อมูลและการสร้างดัชนี (Ingestion and Indexing Phase)
พื้นฐานที่สำคัญที่สุดของระบบ RAG คือความสามารถในการจัดการกับข้อมูลที่ไม่มีโครงสร้าง (Unstructured Data) เพื่อสร้างฐานความรู้ที่เครื่องจักรสามารถทำความเข้าใจได้ กระบวนการนี้เริ่มต้นจากการนำเอกสารต่างๆ มาแบ่งออกเป็นส่วนย่อยหรือที่เรียกว่าการทำ Chunking เพื่อให้สอดคล้องกับข้อจำกัดด้านความยาวของหน้าต่างบริบท (Context Window) ของโมเดลภาษา จากนั้นระบบจะนำเทคโนโลยีปัญญาประดิษฐ์อีกแขนงหนึ่งที่เรียกว่าโมเดลการฝังคำ (Embedding Language Models) มาใช้ในการแปลงข้อความเหล่านี้ให้กลายเป็นชุดตัวเลขทางคณิตศาสตร์แบบเวกเตอร์ (Vector Representations) ที่สามารถสะท้อนความหมายเชิงอรรถศาสตร์ (Semantic Meaning) ของข้อความนั้นๆ ได้อย่างสมบูรณ์ 3 เวกเตอร์เหล่านี้จะถูกนำไปจัดเก็บในฐานข้อมูลเวกเตอร์ (Vector Database) ชั้นนำในอุตสาหกรรมอย่าง ChromaDB, Pinecone, Weaviate หรือ Qdrant ซึ่งถูกออกแบบมาโดยเฉพาะเพื่อรองรับการค้นหาความคล้ายคลึงกันทางเรขาคณิตในพื้นที่มิติสูง 10
ระยะการค้นหาและสืบค้นข้อมูล (Retrieval Phase)
เมื่อผู้ใช้งานป้อนคำถามเข้าสู่ระบบ คำถามนั้นจะถูกส่งผ่านโมเดลการฝังคำตัวเดียวกันเพื่อแปลงเป็นเวกเตอร์คำถาม จากนั้นระบบจะใช้อัลกอริทึมการค้นหาความหมายที่คล้ายคลึงกัน (Semantic Search Methods) เพื่อเปรียบเทียบและวัดระยะห่างระหว่างเวกเตอร์คำถามกับเวกเตอร์ทั้งหมดในฐานข้อมูล 3 ระบบปฏิบัติการค้นหาขั้นสูงในปัจจุบัน อย่างเช่นบริการ Amazon Kendra หรือ Azure AI Search จะไม่หยุดอยู่เพียงแค่การเปรียบเทียบเวกเตอร์ แต่จะบูรณาการกลไกการจัดอันดับความเกี่ยวข้อง (Relevancy Re-rankers) เพื่อเรียงลำดับความสำคัญของเอกสารที่ค้นพบใหม่ และคัดเลือกเฉพาะข้อมูลที่มีความเชื่อมโยงกับเจตนาของผู้ใช้มากที่สุด 1 ในสถาปัตยกรรมแบบดั้งเดิม (Classic RAG Pattern) กระบวนการนี้มักใช้การสืบค้นแบบไฮบริดที่รวมการค้นหาคีย์เวิร์ดเข้ากับการค้นหาเวกเตอร์ ในขณะที่สถาปัตยกรรมแบบตัวแทนอัจฉริยะ (Agentic Retrieval) โมเดลภาษาจะทำหน้าที่วิเคราะห์คำถามที่ซับซ้อนและแตกแขนงออกเป็นคำถามย่อย (Subqueries) หลายข้อเพื่อดึงข้อมูลแบบคู่ขนานจากฐานข้อมูลหลายแหล่ง 14
ระยะการสังเคราะห์และการสร้างผลลัพธ์ (Generation Phase)
ในขั้นตอนสุดท้าย ข้อมูลที่ถูกดึงมาได้จะผ่านการประมวลผลล่วงหน้า (Pre-processing) เพื่อตัดคำที่ไม่มีความหมาย (Stop Words) หรือลดรูปคำ (Stemming) ก่อนจะถูกนำไปบูรณาการเข้ากับคำถามเดิมของผู้ใช้งาน การบูรณาการนี้ใช้เทคนิควิศวกรรมคำสั่ง (Prompt Engineering) เพื่อสร้างคำสั่งที่ได้รับการเสริมบริบท (Augmented Prompt) 1 เมื่อโมเดลภาษาได้รับคำสั่งดังกล่าว โมเดลจะทำการสังเคราะห์คำตอบโดยใช้ความรู้รอบตัวจากการฝึกสอนผนวกเข้ากับข้อเท็จจริงใหม่ที่ปรากฏในบริบท ผลลัพธ์ที่ได้จึงเป็นข้อความที่มีความเป็นธรรมชาติ มีตรรกะที่สมบูรณ์ และมีพื้นฐานรองรับจากหลักฐานเชิงประจักษ์อย่างแท้จริง 3
เทคนิควิศวกรรมการสืบค้นข้อมูลขั้นสูง (Advanced Retrieval Engineering)
สถาปัตยกรรม RAG ในยุคเริ่มต้นที่พึ่งพาเพียงการค้นหาเอกสารผ่านความคล้ายคลึงทางเวกเตอร์ (Naive RAG) มักประสบปัญหาความไร้ประสิทธิภาพเมื่อเผชิญกับชุดข้อมูลที่ซับซ้อน ข้อบกพร่องที่ถูกปิดบังไว้ในบทความแนะนำเบื้องต้นคือ ปัญหาของการที่อัลกอริทึมพิจารณาเพียงการทับซ้อนของคำโดยปราศจากความเข้าใจในโครงสร้างของเอกสาร การสับย่อยเอกสารด้วยโทเค็นแบบตายตัวมักทำลายบริบทที่เชื่อมโยงกัน ส่งผลให้ข้อมูลบางส่วนสูญเสียความหมายดั้งเดิมเมื่อถูกตัดขาดจากหัวข้อย่อยต้นทาง 10 เพื่อแก้ไขสภาวะนี้ วิศวกรรมข้อมูลจึงได้พัฒนาเทคนิคการดึงข้อมูลขั้นสูงอย่างต่อเนื่อง
หนึ่งในวิธีการที่ได้รับความนิยมคือการสืบค้นแบบผสมผสาน (Hybrid Retrieval) ซึ่งถูกนำมาใช้เพื่ออุดช่องโหว่ของการค้นหาเชิงความหมาย (Semantic Search) ที่มักล้มเหลวในการจับคู่คำเฉพาะเจาะจงอย่างเช่น รหัสสินค้า รหัสข้อผิดพลาด หรือเลขที่ใบอนุญาต ด้วยการรวมการค้นหาเวกเตอร์เข้ากับระบบการค้นหาคำสำคัญแบบดั้งเดิม (เช่น BM25) ผ่านกระบวนการผสานอันดับ (Reciprocal Rank Fusion หรือ RRF) ทำให้ระบบสามารถดึงข้อมูลที่ตอบโจทย์ทั้งความหมายและคำสำคัญได้อย่างแม่นยำ 11
นอกจากนี้ การเพิ่มประสิทธิภาพยังเกี่ยวข้องกับการแก้ปัญหาความเหลื่อมล้ำระหว่างคำถามสั้นๆ ของผู้ใช้กับเอกสารอ้างอิงขนาดยาว เทคนิค Hypothetical Document Embeddings (HyDE) เป็นนวัตกรรมที่ออกแบบมาเพื่อแก้ไขปัญหานี้โดยให้ LLM ทำการสร้างคำตอบสมมติหรือเอกสารจำลองขึ้นมาจากคำถามของผู้ใช้งานก่อน จากนั้นระบบจึงนำคำตอบจำลองนี้ไปแปลงเป็นเวกเตอร์เพื่อค้นหาเอกสารจริงในฐานข้อมูล ซึ่งพิสูจน์แล้วว่าช่วยยกระดับความสามารถในการค้นพบเนื้อหา (Recall) โดยไม่ดึงข้อมูลขยะติดมาด้วย 15 ในแง่ของการจัดการเนื้อหาขนาดยาว เทคนิค Parent Document Retrieval และ Multi-vector Retrieval ได้รับการนำมาใช้เพื่อแยกการจัดเก็บระหว่างดัชนีสำหรับสืบค้นและบริบทสำหรับการสร้างคำตอบ ระบบจะสร้างเวกเตอร์จากข้อมูลส่วนย่อยเพื่อความแม่นยำในการค้นหา แต่เมื่อค้นพบแล้ว ระบบจะดึงข้อมูลโครงสร้างหลักหรือเอกสารต้นฉบับฉบับเต็มมาป้อนให้ LLM เพื่อรักษาภาพรวมของเนื้อหาไว้ 15
การจัดเรียงลำดับบริบทก่อนเข้าสู่โมเดลภาษาก็มีความสำคัญไม่แพ้กัน เทคนิค Reverse Packing เป็นกลยุทธ์ที่ใช้ประโยชน์จากพฤติกรรมของ LLMs ที่มักให้ความสำคัญกับข้อมูลบริเวณขอบของหน้าต่างบริบท ด้วยการจัดเรียงเอกสารที่เกี่ยวข้องน้อยที่สุดไว้ตรงกลาง และจัดให้เอกสารที่มีความเกี่ยวข้องสูงสุดอยู่ล่างสุดหรือใกล้กับคำสั่งมากที่สุด ทำให้ LLM สามารถให้ความสนใจกับข้อมูลสำคัญได้อย่างเต็มประสิทธิภาพ 18 อย่างไรก็ตาม แนวทางวิศวกรรมข้อมูลที่น่าจับตามองอีกด้านหนึ่งคือแนวทางที่ปฏิเสธการพึ่งพาฐานข้อมูลเวกเตอร์โดยสิ้นเชิง หรือ Vectorless RAG แนวคิดนี้ชี้ให้เห็นว่าการตั้งค่าระบบฐานข้อมูลเวกเตอร์นั้นเป็นภาระโครงสร้างพื้นฐานที่เกินความจำเป็นสำหรับงานง่ายๆ เครื่องมืออย่าง PageIndex นำเสนอทางเลือกด้วยการแปลงเอกสารให้เป็นโครงสร้างแผนผังต้นไม้ (Navigable Trees) และให้ LLM ใช้เหตุผลเพื่อค้นหาข้อมูลตามลำดับชั้นของโครงสร้างนั้นโดยตรง ซึ่งช่วยแก้ปัญหาการสูญเสียบริบทจากการทำ Chunking ได้อย่างเด็ดขาด 10
การวิเคราะห์เชิงเปรียบเทียบสถาปัตยกรรมทางเลือก: RAG, Fine-Tuning และ Long Context Window
เมื่อองค์กรตัดสินใจพัฒนาระบบปัญญาประดิษฐ์ วิศวกรต้องเผชิญกับทางแยกสำคัญในการเลือกสถาปัตยกรรมที่เหมาะสม ความสับสนที่เกิดขึ้นบ่อยครั้งเกิดจากการเปรียบเทียบวิธีการเหล่านี้ในแง่ของฟีเจอร์การใช้งาน แทนที่จะทำความเข้าใจความแตกต่างทางกลไกเชิงฟิสิกส์ที่อยู่เบื้องหลัง 20 กฎเกณฑ์พื้นฐานที่ควรจดจำคือ การทำ RAG เปลี่ยนแปลงสิ่งที่โมเดลสามารถมองเห็นได้ในขณะประมวลผล (What the model can see right now) ในขณะที่การทำ Fine-tuning คือการเปลี่ยนแปลงพฤติกรรมถาวรของโมเดลผ่านการปรับค่าน้ำหนักพารามิเตอร์ (How the model behaves every time) 20
RAG เปรียบเทียบกับการปรับแต่งโมเดลแบบเฉพาะเจาะจง (Fine-Tuning)
การทำ Fine-tuning เกี่ยวข้องกับการใช้ชุดข้อมูลโดเมนเฉพาะเพื่อฝึกสอนโมเดลเพิ่มเติมจากจุดเริ่มต้น (Pre-trained base) วิธีนี้จะทำการปรับน้ำหนักพารามิเตอร์ภายในเพื่อขัดเกลาความเชี่ยวชาญเฉพาะด้าน เช่น การเข้าใจตรรกะทางการแพทย์ หรือการเขียนโค้ดภาษาคอมพิวเตอร์ 12 การทำ Fine-tuning ไม่ว่าจะเป็นแบบดั้งเดิม (Full Fine-tuning) หรือการใช้เทคนิคที่ประหยัดทรัพยากรอย่าง PEFT (Parameter-Efficient Fine-Tuning) ล้วนแล้วแต่มีข้อได้เปรียบในการควบคุมรูปแบบการตอบสนอง น้ำเสียง ทัศนคติ และความคงเส้นคงวาของโมเดล 12
อย่างไรก็ตาม Fine-tuning มีจุดอ่อนสำคัญที่ทำให้ไม่เหมาะสมกับระบบที่ต้องการการตรวจสอบข้อมูลแบบเรียลไทม์ ประการแรกคือปัญหาการสูญเสียข้อมูลเดิม (Catastrophic Forgetting) ที่โมเดลอาจหลงลืมองค์ความรู้เก่าเมื่อได้รับการฝึกสอนข้อมูลใหม่ ประการที่สองคือความไม่ยืดหยุ่นในการอัปเดตข้อมูล ซึ่งทุกครั้งที่มีการเปลี่ยนแปลงข้อมูลองค์กร วิศวกรจะต้องทำการฝึกสอนใหม่ด้วยคลัสเตอร์หน่วยประมวลผลกราฟิก (GPU Clusters) ซึ่งใช้เวลาและงบประมาณมหาศาล และประการสุดท้ายคือปัญหาด้านความปลอดภัย เนื่องจากความรู้ทั้งหมดถูกเข้ารหัสเป็นน้ำหนักพารามิเตอร์ จึงไม่สามารถลบหรือกำหนดสิทธิ์การเข้าถึงข้อมูลเฉพาะกลุ่มพนักงานได้ ทำให้เสี่ยงต่อการเปิดเผยข้อมูลความลับองค์กร 12
ในทางตรงกันข้าม สถาปัตยกรรม RAG ทำงานโดยแยกส่วนจัดเก็บข้อมูลออกจากตัวโมเดล ทำให้องค์กรสามารถอัปเดตฐานข้อมูลได้อย่างอิสระโดยไม่ต้องแตะต้องโครงข่ายประสาทเทียม RAG จึงมีต้นทุนการบำรุงรักษาในระยะยาวที่ต่ำกว่า มีความยืดหยุ่นสูง ลดอัตราการเกิดอาการประสาทหลอนได้อย่างตรงจุด และมีความโปร่งใสเนื่องจากระบบสามารถระบุลิงก์อ้างอิงไปสู่เอกสารต้นฉบับได้ 8 ปัจจุบัน องค์กรระดับสูงมักเลือกใช้แนวทางไฮบริดหรือที่รู้จักในชื่อ Retrieval-Augmented Fine-Tuning (RAFT) ซึ่งผสมผสานจุดแข็งของทั้งสองวิธีเข้าด้วยกัน โดยการใช้โมเดลที่ผ่านการ Fine-tune ให้มีความเชี่ยวชาญในภาษาเฉพาะทาง มาทำหน้าที่เป็นสมองกลหลักที่ดึงข้อมูลเรียลไทม์ผ่านกลไกของ RAG 21
| เกณฑ์การเปรียบเทียบระดับวิศวกรรม | Retrieval-Augmented Generation (RAG) | Fine-Tuning (รวมถึง PEFT / LoRA) |
| การเข้าถึงข้อมูลใหม่หรือเรียลไทม์ | มีประสิทธิภาพสูง ข้อมูลถูกอัปเดตทันที 21 | ไม่มีประสิทธิภาพ ต้องทำการฝึกสอนโมเดลใหม่ 21 |
| ความเชี่ยวชาญเฉพาะโดเมนเชิงลึก | อาศัยความเข้าใจเดิมของโมเดลพื้นฐาน 21 | สูงมาก สามารถปรับเปลี่ยนตรรกะลึกซึ้งได้ 21 |
| ความสามารถในการอธิบายอ้างอิง | ชัดเจน สามารถชี้แหล่งข้อมูลต้นฉบับได้ 21 | ต่ำ ข้อมูลถูกฝังตัวอยู่ในค่าน้ำหนักโครงข่าย 21 |
| ทรัพยากรการคำนวณช่วงเตรียมการ | ต่ำกว่า (มุ่งเน้นการวางท่อข้อมูล) 21 | สูงมาก (ใช้การประมวลผลเครือข่ายประสาทเทียม) 21 |
| ทรัพยากรการคำนวณช่วงการใช้งาน | สูง (จากการดึงข้อมูลร่วมกับการอนุมาน) 21 | ต่ำ (ทำกระบวนการอนุมานโดยตรง) 21 |
| การควบคุมสไตล์การตอบสนอง | ทำได้ผ่านวิศวกรรมคำสั่ง แต่อาจไม่คงที่ 21 | มีความคงเส้นคงวาและเป็นธรรมชาติสูง 21 |
| ความปลอดภัยของข้อมูล | สูงมาก สามารถแบ่งแยกสิทธิ์ตามผู้ใช้งาน 21 | มีความเสี่ยงที่ข้อมูลความลับจะรั่วไหลผ่านการถาม 21 |
RAG เปรียบเทียบกับการขยายหน้าต่างบริบท (Long Context Window)
ในห้วงปี 2025 เป็นต้นมา อุตสาหกรรมได้ประจักษ์ถึงความก้าวหน้าของโมเดลที่มีความสามารถในการรับหน้าต่างบริบท (Context Window) ขนาดมหาศาล เช่น แพลตฟอร์มที่เปิดให้ใช้งานพื้นที่บริบทมากถึง 1 ล้านโทเค็น ซึ่งเทียบเท่ากับหน้ากระดาษ A4 จำนวนกว่า 2,000 หน้า นวัตกรรมนี้จุดประกายคำถามที่ว่า หากความจุในการรับรู้ของโมเดลมีปริมาณเกินกว่าปริมาณข้อมูลที่มีอยู่ทั้งหมด องค์กรควรจะยุติการใช้ระบบ RAG แล้วป้อนข้อมูลทั้งหมดลงในคำสั่ง (Prompt) ในรวดเดียวเลยหรือไม่ 1
การวิเคราะห์เชิงลึกเผยให้เห็นว่าการขยายหน้าต่างบริบทไม่สามารถทดแทน RAG ได้อย่างสมบูรณ์แบบในระดับการใช้งานที่ต้องการประสิทธิภาพสูง (Production scale) ทั้งนี้เกิดจากข้อจำกัดทางวิศวกรรมและเศรษฐศาสตร์สามประการหลัก ประการแรก ปัญหาความหน่วง (Latency) กระบวนการทำงานแบบกลไกความสนใจของทรานส์ฟอร์เมอร์ (Transformer Attention) จะทวีคูณการคำนวณตามสัดส่วนปริมาณโทเค็นในลักษณะความซับซ้อนเชิงเวลาแบบยกกำลังสอง () การป้อนข้อมูล 1 ล้านโทเค็นอาจทำให้เกิดความหน่วงนานหลายนาทีก่อนที่โมเดลจะเริ่มสร้างโทเค็นแรก (Time to first token) 25 ประการที่สอง โครงสร้างทางเศรษฐศาสตร์ (Cost Economics) การประมวลผลข้อมูล 1 ล้านโทเค็นต่อ 1 การสืบค้นอาจมีต้นทุนที่ระดับ 2 ดอลลาร์สหรัฐ ในขณะที่กระบวนการเรียกใช้ RAG จะเสียค่าใช้จ่ายเฉลี่ยเพียง 0.00008 ดอลลาร์สหรัฐต่อการสืบค้น เมื่อประยุกต์ใช้กับแอปพลิเคชันที่มีการเข้าใช้งานระดับพันครั้งต่อวัน ความแตกต่างด้านงบประมาณที่ห่างกันถึง 1,250 เท่าจึงถือเป็นปัจจัยชี้ขาด 28
ประการสุดท้าย แม้โมเดลหน้าต่างบริบทขนาดใหญ่จะแสดงศักยภาพเหนือกว่าในงานที่ต้องทำความเข้าใจภาพรวมของเอกสารทั้งฉบับหรือการใช้เหตุผลเชิงลึกข้ามโครงสร้าง ทว่าสถาปัตยกรรม RAG กลับยังคงความได้เปรียบอย่างชัดเจนสำหรับงานที่ต้องการการดึงข้อเท็จจริงที่แม่นยำ พร้อมการตรวจสอบแหล่งที่มาอย่างเคร่งครัด รวมถึงการแก้ไขข้อจำกัดด้วยแคชการค้นหา (KV cache reuse) ก็ทำได้เพียงจำกัดในกรณีใช้งานที่ตายตัว 25
การประเมินและวัดผลระบบ RAG ระดับวิสาหกิจ (Enterprise RAG Evaluation and Metrics)
การตรวจจับและวิเคราะห์คุณภาพในกระบวนการทำงานของระบบ RAG ถือเป็นสิ่งจำเป็นสำหรับการประกันความเสถียรในสภาพแวดล้อมที่คาดหวังผลสัมฤทธิ์ การใช้ดุลยพินิจของมนุษย์มีความล่าช้าและใช้งบประมาณสูง อุตสาหกรรมจึงได้พึ่งพาแพลตฟอร์มการประเมินผลอัตโนมัติ (Evaluation Frameworks) เช่น RAGAS, DeepEval, TruLens, WandB, และ Patronus AI เพื่อทำหน้าที่ตรวจสอบทั้งชั้นการดึงข้อมูลและชั้นการสร้างผลลัพธ์ผ่านการใช้ LLM ในการตัดสิน (LLM-as-a-judge) 29
กรอบการประเมินมาตรฐานอุตสาหกรรมอย่าง RAGAS กำหนดให้มีการวิเคราะห์ผ่าน 4 ดัชนีชี้วัดหลัก (Metrics) ที่ทำงานแยกส่วนกันเพื่อการวิเคราะห์ข้อบกพร่องที่แม่นยำ 30
- ความซื่อสัตย์ต่อฐานข้อมูล (Faithfulness): เป็นดัชนีที่วัดอัตราการเกิดอาการประสาทหลอนของเครื่องกำเนิดข้อความ (Generator) กระบวนการนี้จะประเมินว่าข้อความหรือข้ออ้างทุกประการที่ถูกสร้างขึ้นในผลลัพธ์นั้น ได้รับการสนับสนุนโดยข้อเท็จจริงที่ปรากฏในบริบทที่ถูกดึงมาอย่างครบถ้วนหรือไม่ 29
- ความสอดคล้องของคำตอบ (Answer Relevancy): ดัชนีชี้วัดนี้ไม่สนใจว่าข้อเท็จจริงนั้นถูกต้องหรือไม่ แต่มุ่งประเมินว่าเจตนาในการตอบสนองนั้นตรงกับคำถามที่ผู้ใช้ถามมาหรือไม่ หรือมีแนวโน้มที่จะตอบเบี่ยงประเด็นและให้ข้อมูลที่ไม่จำเป็น 29
- ความครอบคลุมของบริบท (Context Recall): ตัวชี้วัดประสิทธิภาพฝั่งตัวดึงข้อมูล (Retriever) โดยประเมินว่าชุดเอกสารที่ระบบนำมาเป็นบริบทนั้น มีข้อมูลที่จำเป็นเพียงพอต่อการสร้างคำตอบที่ถูกต้องตามอุดมคติ (Gold standard response) หรือไม่ หากคะแนนต่ำ แสดงว่าท่อลำเลียงข้อมูลทำความเข้าใจเอกสารได้ไม่ดีพอ 29
- ความแม่นยำของบริบท (Context Precision): เน้นย้ำความสามารถด้านการเรียงลำดับเนื้อหา (Ranking) โดยตรวจสอบว่าระบบสามารถจำแนกและวางเนื้อหาที่มีระดับความเกี่ยวข้องสูงสุดไว้ในอันดับต้นๆ ของรายการเอกสารที่ดึงมาได้หรือไม่ เพื่อให้ LLM รับรู้ถึงลำดับความสำคัญก่อนหลัง 34
เมื่อเปรียบเทียบในเชิงวิศวกรรมซอฟต์แวร์ แพลตฟอร์ม DeepEval มอบความสามารถในการตรวจแก้จุดบกพร่อง (Debugging) อย่างละเอียด การทำงานแบบกักกรอบด้วย JSON และการบูรณาการเข้ากับท่อส่งข้อมูลการทำงานร่วมกันต่อเนื่อง (CI/CD Pipelines) อย่างเต็มรูปแบบ ซึ่งเหมาะสมกับนักพัฒนามากกว่า TruLens ที่โดดเด่นในด้านการสังเกตการณ์ระบบแบบเรียลไทม์ (Runtime monitoring) ขณะที่จากการสำรวจเชิงเปรียบเทียบพบว่า WandB สามารถระบุตำแหน่งของเอกสารได้อย่างแม่นยำสูงสุด (Top-1 Accuracy 94.5%) แต่ TruLens กลับมีอัตราการแยกแยะเนื้อหาที่ถูกแก้ไขหลอกๆ ได้ดีกว่า (Discrimination ratio) แม้ว่าเครื่องมือทั้งหมดในตลาดยังคงมีช่องโหว่ในการแยกแยะบริบทที่ผิดพลาดเชิงข้อเท็จจริง (Factually wrong) ก็ตาม 30

ความมั่นคงปลอดภัย การควบคุมการเข้าถึง และธรรมาภิบาลข้อมูลในสถาปัตยกรรม RAG
การนำระบบ RAG มาติดตั้งใช้งานในองค์กรถือเป็นการขยายพื้นที่ผิวการโจมตี (Attack Surface) ด้านความปลอดภัยทางไซเบอร์ออกไปอย่างกว้างขวาง สถาปัตยกรรม RAG สืบทอดจุดอ่อนของ LLMs แบบดั้งเดิมในเรื่องการจดจำข้อมูลและการถูกหลอกลวงด้วยคำสั่งโจมตี (Adversarial Prompts) ไปพร้อมๆ กับการเปิดช่องโหว่ใหม่จากการพึ่งพาแหล่งข้อมูลความรู้ภายนอก ซึ่งนำไปสู่ความเสี่ยงต่อการรั่วไหลของข้อมูลที่ถูกดึง และการปนเปื้อนของข้อมูล (Data Poisoning) ด้วยเจตนามุ่งร้ายเพื่อบิดเบือนพฤติกรรมของโมเดล 38 ระบบความปลอดภัยจึงต้องครอบคลุมการควบคุมตลอดทุกเฟสของท่อส่งข้อมูล
ในระดับพื้นที่จัดเก็บ การจัดการวงจรชีวิตข้อมูลต้องตั้งอยู่บนฐานข้อบังคับความเป็นส่วนตัวระดับสากล เช่น ข้อกำหนด GDPR หรือ CCPA ระบบควรติดตั้งกระบวนการลบและจำลองตัวตนเพื่อปิดบังข้อมูลส่วนบุคคลที่ละเอียดอ่อน (PII Redaction) โดยอาจพึ่งพาซอฟต์แวร์คัดกรองอย่าง Microsoft Presidio หรือ Amazon Comprehend ก่อนที่ข้อมูลจะถูกฝังค่าลงในดัชนี นอกจากนี้ ฐานข้อมูลเวกเตอร์จะต้องถูกจัดเก็บในรูปแบบที่ไม่สามารถแก้ไขได้หรือ WORM (Write-Once, Read-Many) ควบคู่ไปกับระบบควบคุมเวอร์ชันเพื่ออำนวยความสะดวกในการย้อนกลับระบบทันทีหากพบเจอกรณีข้อมูลถูกปนเปื้อน 13
กระบวนทัศน์การรักษาความปลอดภัยของระบบ RAG ที่สำคัญที่สุดคือสถาปัตยกรรมควบคุมการเข้าถึงแบบอิงตามบทบาท (Role-Based Access Control หรือ RBAC) ข้อมูลขององค์กร ไม่ว่าจะเป็นรายงานการแพทย์ที่มีชั้นความลับระหว่างแพทย์กับพยาบาล หรือนโยบายการเงิน ล้วนต้องถูกตีกรอบสิทธิ์การเข้าถึงอย่างเคร่งครัด ระบบที่รัดกุมจะต้องดำเนินการบังคับใช้สิทธิ์ (Permission checks) ในขั้นตอนของการค้นหาเวกเตอร์ก่อนที่จะดึงข้อมูลมาประกอบเป็นบริบท เพื่อป้องกันไม่ให้โมเดลได้รับข้อมูลที่อยู่นอกเหนือขอบเขตของผู้ปฏิบัติงาน 14 การปฏิบัติตามมาตรฐานระดับสูง อาทิ กรอบโครงสร้าง NIST AI RMF หรือข้อกำหนด SOC 2 Type II ยังบังคับให้สถาปัตยกรรมมีการบันทึกประวัติการตรวจสอบ (Audit Logging) ในระดับที่มีความละเอียดสูง ครอบคลุมถึงเอกลักษณ์ของผู้ใช้งาน เอกสารเฉพาะเจาะจงที่ถูกอ้างอิง และตัวชี้วัดความน่าเชื่อถือ ซึ่งโครงสร้าง Vector Database ในตลาด ณ ปัจจุบันส่วนใหญ่ไม่ได้ออกแบบการบันทึกระดับสูงนี้มาแต่กำเนิด วิศวกรจึงจำเป็นต้องประยุกต์ใช้แพลตฟอร์มผู้ควบคุมข้อมูลอย่าง Privacera หรือ Rubrik Annapurna เป็นเลเยอร์ควบคุมที่ฝั่งแอปพลิเคชันเพื่ออุดช่องโหว่ดังกล่าว 13
เฟรมเวิร์กการพัฒนาชั้นนำ: การเปรียบเทียบสมรรถนะระหว่าง LangChain และ LlamaIndex ประจำปี 2026
เทคโนโลยี RAG ขับเคลื่อนได้ด้วยเฟรมเวิร์กที่เป็นหัวใจสำคัญในการประสานงานระหว่างแหล่งข้อมูล ฐานข้อมูลเวกเตอร์ และโมเดลภาษา ในปี 2026 สองคู่แข่งที่ครอบครองพื้นที่โอเพนซอร์สของอุตสาหกรรมนี้คือ LangChain และ LlamaIndex ซึ่งถึงแม้จะมีเป้าหมายในการพัฒนาแอปพลิเคชันบนโครงสร้าง RAG เหมือนกัน แต่ทั้งสองต่างมีปรัชญาการออกแบบโครงสร้างทางวิศวกรรมที่แตกต่างกันอย่างสิ้นเชิง 42
LlamaIndex ถูกสร้างขึ้นมาโดยมุ่งเน้นความเชี่ยวชาญด้านสถาปัตยกรรมการรับและการสืบค้นข้อมูลเป็นหลัก (Data and Retrieval-first) ปรัชญาของ LlamaIndex นำเสนอโครงสร้างการจัดการผ่านรหัสโปรแกรมที่เรียบง่าย เข้าใจง่ายแบบ Pythonic และมีการตั้งค่าเริ่มต้น (Sensible defaults) ที่ทรงพลัง เหมาะสำหรับการเร่งกระบวนการนำขึ้นใช้งานจริง โครงสร้างของ LlamaIndex โดดเด่นในด้านการบริหารจัดการดัชนีของเอกสารขนาดยาว การรักษาสายสัมพันธ์เชิงบริบทระหว่างเอกสาร (Context-aware document relationships) และมีข้อได้เปรียบที่ชัดเจนจากการทดสอบประสิทธิภาพด้านความเร็วในการค้นหาที่เหนือกว่า LangChain อย่างน้อยร้อยละ 40 ทำให้เฟรมเวิร์กนี้เป็นทางเลือกที่สมบูรณ์แบบสำหรับงานพัฒนาระบบสืบค้นระดับองค์กรที่เน้นข้อมูลแบบคงที่และการตอบคำถามจากคู่มือที่ซับซ้อน 42
ในฝั่งตรงกันข้าม LangChain ถูกออกแบบบนกระบวนทัศน์ที่เน้นการประสานงานของระบบอัจฉริยะ (Orchestration-first) สถาปัตยกรรมมุ่งเน้นความเป็นโมดูลาร์ที่เปิดโอกาสให้นักพัฒนาเข้าควบคุมเชิงลึกและปรับแต่งองค์ประกอบทุกประการ ไม่ว่าจะเป็นหน่วยความจำแบบยาว การกำหนดพฤติกรรมตัวแทนอัจฉริยะ (Agents) และการสร้างห่วงโซ่การเชื่อมต่อ (Chains) ไปยังบริการภายนอกหรือระบบบูรณาการทางธุรกิจที่กว้างขวาง เช่น Salesforce, Microsoft 365 หรือฐานข้อมูล API ต่างๆ 42
การสำรวจสมรรถนะการเปรียบเทียบมาตรฐาน (Benchmarking) ภายใต้สภาวะควบคุมเดียวกัน (โดยใช้โมเดล GPT-4.1-mini, BGE-small, Qdrant และรันแบบทดสอบรวม 100 รอบ) เผยให้เห็นว่าเฟรมเวิร์กไม่ได้ส่งผลกระทบต่อประสิทธิภาพจนถึงระดับวิกฤต ความหน่วงของสถาปัตยกรรม (Framework Overhead) ทั้งหมดพบว่าอยู่ระหว่าง 3-14 มิลลิวินาทีต่อการสอบถามเท่านั้น ซึ่งสะท้อนว่าเวลาส่วนใหญ่ของระบบหมดไปกับการเข้าออกพอร์ตเครือข่ายและการติดต่อเชื่อมต่อกับภายนอก ไม่ใช่ความบกพร่องในตรรกะภายในของเฟรมเวิร์ก 46 ทัศนะในแวดวงนักพัฒนาแนะนำว่า การพัฒนาโซลูชันระดับโลกอาจใช้การออกแบบไฮบริด โดยมอบหมายให้ LlamaIndex ควบคุมท่อสืบค้นข้อมูล และใช้ LangGraph จัดการกระบวนการตัดสินใจหลายขั้นตอนของตัวแทนอัจฉริยะ 42
| ตัวชี้วัด / คุณสมบัติ | LangChain / LangGraph | LlamaIndex |
| ปรัชญาแนวคิด | มุ่งเน้นการควบคุมการประมวลผลโมดูลาร์ (Orchestration-first) 44 | มุ่งเน้นกระบวนการและตรรกะของข้อมูล (Retrieval-first) 44 |
| ความเร็วในการสืบค้นข้อมูล | ประสิทธิภาพระดับมาตรฐาน 42 | รวดเร็วกว่า LangChain ประมาณร้อยละ 40 42 |
| เส้นโค้งการเรียนรู้ | ชันสูง เนื่องจากความเป็นโมดูลาร์ที่เปิดช่องความซับซ้อน 42 | ราบเรียบ ใช้โครงสร้างความคุ้นเคยแบบ Pythonic ที่ชัดเจน 42 |
| ขีดความสามารถการใช้งานร่วม | รองรับเครื่องมือ ฐานข้อมูล และโครงข่ายตัวแทนซับซ้อนได้อย่างมหาศาล 42 | เน้นกระบวนการนำเข้าและเชื่อมโยงชุดข้อมูลขนาดใหญ่ขององค์กร 42 |

กรณีศึกษาเชิงประจักษ์: อุตสาหกรรมระดับโลกและการประยุกต์ใช้เทคโนโลยีภาษาไทย
ความสามารถในการประยุกต์ใช้งานของระบบ RAG ได้สร้างผลกระทบต่อประสิทธิภาพการทำงานในสาขาต่างๆ อย่างมีนัยสำคัญ ในระดับสากล วิสาหกิจอย่างแพลตฟอร์มจัดส่งอาหาร DoorDash ประยุกต์ใช้แชตบอตขับเคลื่อนด้วย RAG เพื่อเป็นศูนย์กลางสนับสนุนพนักงานจัดส่ง ลดภาระพนักงานคอลเซ็นเตอร์ด้วยการกรองปัญหาสอบถามผ่านระเบียบปฏิบัติและนโยบายภายในที่เปลี่ยนแปลงอยู่เสมอได้อย่างสมบูรณ์แบบ ในขณะที่บริษัทข้ามชาติอย่าง LinkedIn ใช้ RAG เสริมกำลังด้วยเทคนิคกราฟความรู้ (Knowledge Graph) สำหรับจัดการคำถามสนับสนุนทางเทคนิคของลูกค้า 47 นอกเหนือจากงานบริการลูกค้าแล้ว สถาปัตยกรรม RAG ยังสร้างการเปลี่ยนแปลงขั้นวิกฤตในอุตสาหกรรมการเงิน ผ่านการสรุปภาวะตลาดและการสนับสนุนบุคลากรระดับผู้บริหาร ส่วนในวงการการแพทย์และกฎหมาย การสืบค้นฐานข้อมูลข้อบังคับและกฎระเบียบที่ถูกต้องแม่นยำเป็นเครื่องมือช่วยยกระดับสติปัญญาของมนุษย์ในการวินิจฉัยได้อย่างทรงพลัง 7
กรณีศึกษาภายในประเทศไทย: ความร่วมมือระหว่าง EPG และสถาบันการศึกษา
ความก้าวหน้าของ RAG ภายในประเทศได้รับการพิสูจน์ศักยภาพผ่านนวัตกรรมของกลุ่มบริษัทอีสเทิร์นโพลีเมอร์ กรุ๊ป (EPG) โดยมอบหมายให้บริษัทแอร์โรคลาส (AEROKLAS) ร่วมมือเชิงลึกกับสถาบันวิทยาการหุ่นยนต์ภาคสนาม (FIBO) และมหาวิทยาลัยเทคโนโลยีพระจอมเกล้าธนบุรี (KMUTT) โครงการนำร่องนี้มุ่งพัฒนาฐานความรู้ดิจิทัลเพื่อสนับสนุนการค้นหาข้อมูลคู่มือ วิดีโออบรม การดำเนินงาน และกระบวนการผลิตในอุตสาหกรรม 50
สถาปัตยกรรมที่พัฒนาขึ้นอยู่บนระบบโครงสร้างแบบบริการระดับจุลภาค (Microservices) โดยประกอบด้วย
- แอปพลิเคชันส่วนหน้าบนเว็บฟลัตเทอร์ (Flutter Web Application) ที่เน้นความง่ายในการใช้งาน
- ฐานข้อมูลเวกเตอร์แบบ Milvus สำหรับการจัดเก็บข้อมูลเชิงลึก
- เครื่องมือจัดการเวิร์กโฟลว์อัตโนมัติ n8n
- สถาปัตยกรรมตัวประมวลผลภาษาธรรมชาติ Google Gemini 2.0 Flash API ควบคู่กับกระบวนการยืนยันตัวตน SSO และการเข้ารหัสรักษาความปลอดภัยระดับองค์กร AES-256 50
ผลสัมฤทธิ์ของระบบประจักษ์ชัดผ่านการยกระดับโครงสร้างธุรกิจอย่างรอบด้าน โดยสามารถลดระยะเวลาในการค้นหาข้อมูลของพนักงานลงได้มหาศาลถึงร้อยละ 60-80 เพิ่มสมรรถนะระบบนิเวศการทำงานโดยรวมร้อยละ 20-25 และเตรียมรับมือลดต้นทุนกระบวนการงานประจำเป็นเป้าหมายระหว่างร้อยละ 10 ไปจนถึงร้อยละ 30 ในแผนพัฒนาระยะกลาง ซึ่งแสดงให้เห็นศักยภาพของการผสานปัญญาประดิษฐ์ในอุตสาหกรรมการผลิตแบบดั้งเดิมได้อย่างไร้ที่ติ 50
ศักยภาพด้านแบบจำลองภาษาไทย
กุญแจสำคัญที่ขับเคลื่อนระบบ RAG ให้ทำงานกับเนื้อหาภาษาไทยอย่างมีประสิทธิภาพคือโมเดลการฝังคำและตัวประมวลผลเจตนา จากผลการประเมินชุดข้อมูลทดสอบประสิทธิภาพระดับองค์กร 15 สาขา พบว่าโมเดลหลายระดับขนาดถูกสร้างให้รองรับเนื้อหาภาษาไทยได้อย่างก้าวกระโดด โครงข่ายที่ขับเคลื่อนอย่างโดดเด่น เช่น Qwen3-Embedding-4B ขึ้นครองความเป็นผู้นำบนดัชนีคะแนนเฉลี่ยที่ 74.41 ตามมาด้วย KaLM-Gemma3-12B และโมเดลตระกูลอเนกประสงค์อย่าง bge-m3 หรือ jina-v5 51
| รายชื่อโมเดลการฝังคำ (Embedding Models) | ระดับคะแนนเฉลี่ยบนดัชนีทดสอบภาษาไทย |
| Qwen3-Embedding-4B | 74.41 52 |
| KaLM-Gemma3-12B | 73.92 52 |
| BOOM_4B_v1 | 71.84 52 |
| jina-v5-text-small | 71.69 52 |
| bge-m3 | 64.77 52 |
เมื่อเทียบเคียงกับโมเดลภาษาในหมวดการให้เหตุผล (Reasoning) โครงการวิจัยแห่งชาติอย่าง OpenThaiGPT ได้แสดงวิวัฒนาการล่าสุดบนฐานของโมเดล Qwen v2.5 ในรหัส OpenThaiGPT 1.5 ซึ่งได้รับการขัดเกลาเจตนาผ่านคำสั่งจับคู่ภาษาไทยสูงกว่า 2 ล้านระเบียน โครงข่ายอัจฉริยะนี้มาพร้อมกับความสามารถในการสนทนาต่อเนื่อง รองรับสถาปัตยกรรม RAG ในตัวและสนับสนุนการเรียกดึงชุดคำสั่ง API ภายนอก (Tool-calling) ได้อย่างเสถียร นอกจากนี้ โครงข่ายตระกูล WangchanBERTa และ SeaLLM ยังคงมีนัยสำคัญในงานประมวลผลชั้นต้นที่เกี่ยวข้องกับภาษาทางกฎหมายหรือระบบรับแจ้งปัญหา เพื่อสร้างข้อได้เปรียบทางด้านภาษาและเจตจำนงเชิงกลยุทธ์ให้ธุรกิจไทย 52
ทิศทางแห่งอนาคตและกรอบสถาปัตยกรรมอุบัติใหม่ประจำปี 2026 (Future Trends 2026)
การวิเคราะห์พลวัตของระบบ RAG พบว่าภูมิทัศน์ของปัญญาประดิษฐ์องค์กรในช่วงปี 2025 และก้าวเข้าสู่ปี 2026 นั้นมีการปรับเปลี่ยนแนวทางอย่างมีนัยสำคัญ ความพยายามในการปรับแต่งเพียงพารามิเตอร์ของหน้าต่างดึงข้อมูลหรือกระบวนการดึงเนื้อหาเชิงเส้นได้ล้าสมัยไปแล้ว อุตสาหกรรมมุ่งสู่กระบวนทัศน์ของ Agentic RAG ที่ตัวประมวลผลทำหน้าที่บริหารโครงข่ายเชิงปัญญา (Intelligence Orchestration) และตรรกะแห่งการตรวจสอบตัวเอง 56 สัญญาณแห่งการเปลี่ยนแปลงเหล่านี้ปรากฏเด่นชัดผ่านแนวโน้มสำคัญห้าประการ
ประการแรก การปฏิเสธความลึกเพื่อโอบรับความกว้างของการสืบค้น (Retrieval Breadth over Depth) ความผิดพลาดที่พบบ่อยไม่ได้เกิดจากระบบค้นพบเนื้อหาที่สัมพันธ์กันน้อยเกินไป แต่เป็นเพราะข้อมูลเชิงประจักษ์ถูกฝังอยู่ตามแหล่งต่างๆ การเปลี่ยนแปลงนี้นำไปสู่เทคโนโลยีที่เรียกว่ากลไกสืบค้นแบบผสานศูนย์กลาง (Unified Retrieval Engines) ที่รวมการค้นหาเวกเตอร์ เอกสารข้อความ ฐานข้อมูลทศนิยมเชิงตรรกะ และบันทึกข้อมูลแบบเรียลไทม์ ไว้บนการควบคุมชั้นเดียว 58 ประการที่สอง ทฤษฎีความสัมพันธ์ส่วนปลาย (Late Interaction Retrieval) ระบบดั้งเดิมนำเสนอการรวบรวมเวกเตอร์ของบทความทั้งหมดมาเปรียบเทียบกัน ซึ่งลดทอนเอกลักษณ์ของคำลงไป ในสถาปัตยกรรมแบบจำลองโครงสร้าง ColBERT กระบวนการค้นหาจะสงวนโทเค็นทุกหน่วยไว้อย่างครบถ้วนจนถึงเสี้ยววินาทีสุดท้าย ทำให้สามารถจับคู่เจตนาที่เฉพาะเจาะจงในหน้ากระดาษที่ลึกที่สุดได้อย่างไม่คลาดเคลื่อน 58
ประการที่สาม ការสตรีมและนำเข้าข้อมูลแบบต่อเนื่อง (Streaming Ingestion) วงจรการอัปเดตระบบด้วยกระบวนการสร้างดัชนีแบบกลุ่ม (Batch Processing) ได้กลายเป็นความล้าหลัง ระบบที่ใช้งานในสถานการณ์ความเสี่ยงสูงอย่างภาคบริการการเงินหรือการควบคุมเครื่องจักรไม่สามารถทนทานต่อข้อมูลเก่า (Stale Knowledge) ระบบรุ่นใหม่ในฐานข้อมูลแบบเวกเตอร์สามารถนำข้อมูลเข้าใหม่ให้พร้อมรองรับคำสั่งค้นหาได้แบบสดทันที 58 ประการที่สี่ ห่วงโซ่การค้นหาและเสริมบริบทที่แก้ไขตนเอง (Self-RAG และ Corrective RAG) ระบบพัฒนาลูปการประเมินกลับเพื่อเปิดโอกาสให้โมเดลตรวจสอบข้อบกพร่อง วิจารณ์ความแม่นยำของผลลัพธ์ที่ได้จากการค้นหา และสั่งให้โมเดลเปิดการสืบค้นเว็บเสริมเพื่อเติมเต็มช่องว่างทางตรรกะได้อย่างสมบูรณ์แบบก่อนส่งให้ผู้ใช้งาน 19
และประการสุดท้าย กลยุทธ์การสืบค้นคาดการณ์ (Speculative Retrieval) ในสภาพแวดล้อมที่ผู้ใช้อาจมีคำถามต่อเนื่องเป็นพหุภาคี สถาปัตยกรรม RAG จะคาดคะเนทิศทางเจตนารมณ์ถัดไป เช่น เมื่อผู้ใช้ซักถามรายได้ในไตรมาสที่สาม ระบบจะคาดเดาและค้นหาอัตราส่วนผลกำไรหรือข้อมูลเชิงเปรียบเทียบในอดีตล่วงหน้า ซ่อนความหน่วงของเครือข่ายไว้เบื้องหลัง เพื่อสร้างการสนทนาที่สัมผัสได้ถึงความรวดเร็วเหนือจินตนาการ 58 ทั้งหมดนี้ล้วนเป็นเครื่องยืนยันว่ากลไกของ GraphRAG ได้ผันตัวจากเพียงแหล่งเก็บข้อมูลมาสู่ศูนย์กลางแห่งการให้เหตุผลทางเรขาคณิต (Reasoning Engines) เป็นที่เรียบร้อยแล้ว 58
บทสรุปเชิงนโยบายและทิศทางเทคโนโลยี
การพิจารณาสถาปัตยกรรม Retrieval-Augmented Generation อย่างละเอียดลออภายใต้กรอบการวิเคราะห์ของวิทยาการคอมพิวเตอร์สมัยใหม่ได้นำไปสู่ข้อสรุปที่เด่นชัด RAG ไม่ใช่เพียงโครงสร้างส่วนควบหรือเทรนด์ชั่วคราวบนโลกของปัญญาประดิษฐ์ ทว่ามันคือกระดูกสันหลังทางเทคโนโลยีและกลไกหลักที่จะนำโมเดลภาษาขนาดใหญ่มาบูรณาการเป็นความรู้ขององค์กรในศตวรรษแห่งข้อมูล สถาปัตยกรรมนี้ได้สร้างดุลยภาพที่ยอดเยี่ยมระหว่างการยับยั้งความผิดพลาดทางความคิด การประหยัดทรัพยากรการประมวลผลอันมีมูลค่ามหาศาล และความสามารถที่เหนือชั้นในการควบคุมการเข้าถึงข้อมูลตามนโยบายความเป็นส่วนตัวและกรอบธรรมาภิบาลข้อมูล
ถึงแม้โลกจะต้องเผชิญกับการยกระดับความสามารถในการรองรับหน้าต่างบริบทอย่างมหาศาล หรือวิธีการปรับแต่งโมเดลโครงข่ายส่วนย่อยที่ก้าวหน้า แต่ขอบเขตเศรษฐศาสตร์ กลไกทางเวลาแฝง และเหตุผลในการตรวจสอบย้อนกลับได้ ยังคงตอกย้ำถึงความได้เปรียบโดยสมบูรณ์ของระบบ RAG แนวโน้มอุตสาหกรรมในยุคตัวแทนอัจฉริยะกำลังผลักดันเทคโนโลยีไปสู่จุดเชื่อมต่อที่ลื่นไหล การปรับประยุกต์และสร้างนวัตกรรมภายในประเทศไทยด้วยความร่วมมือระดับองค์กร ย่อมก่อให้เกิดผลสัมฤทธิ์ที่มีนัยสำคัญระดับสากล วิสาหกิจใดที่ตระหนักถึงขุมพลังแห่งวงจร RAG ที่ขยายไปถึงขั้นการคาดการณ์เชิงพหุกลไก องค์กรนั้นจะสามารถขับเคลื่อนธุรกิจ ก้าวข้ามข้อจำกัดของโครงข่ายประสาทเทียม สร้างความเชื่อมั่นจากผู้บริโภค และเปลี่ยนรูปแบบการใช้ความรู้เชิงสถาบันไปตลอดกาล
ผลงานที่อ้างอิง
- What is Retrieval-Augmented Generation (RAG)? – Google Cloud, เข้าถึงเมื่อ เมษายน 12, 2026 https://cloud.google.com/use-cases/retrieval-augmented-generation
- What is RAG (Retrieval Augmented Generation)? – IBM, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.ibm.com/think/topics/retrieval-augmented-generation
- What is RAG? – Retrieval-Augmented Generation AI Explained – AWS, เข้าถึงเมื่อ เมษายน 12, 2026 https://aws.amazon.com/what-is/retrieval-augmented-generation/
- 15 Important RAG Terms You Need to Know | by Aashish Kumar | Mar, 2026, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@aashishkumar_77032/15-important-rag-terms-you-need-to-know-b5179e45d7ca
- What is RAG? Retrieval-Augmented Generation Explained, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.youtube.com/watch?v=KNvkUH50xXM
- What Is Retrieval-Augmented Generation aka RAG | NVIDIA Blogs, เข้าถึงเมื่อ เมษายน 12, 2026 https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
- Retrieval Augmented Generation use cases for enterprise – Indigo.ai, เข้าถึงเมื่อ เมษายน 12, 2026 https://indigo.ai/en/blog/retrieval-augmented-generation/
- What are RAG models? A guide to enterprise AI in 2025 – Glean, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.glean.com/blog/rag-models-enterprise-ai
- The RAG Architecture: Ingestion and Retrieval with Embeddings and Vector Search | by Mehmet Ozkaya, เข้าถึงเมื่อ เมษายน 12, 2026 https://mehmetozkaya.medium.com/the-rag-architecture-ingestion-and-retrieval-with-embeddings-and-vector-search-9bb86adb0ff5
- Build a RAG System Without Embeddings or Vector Databases | by Reliable Data Engineering | Mar, 2026, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@reliabledataengineering/build-a-rag-system-without-embeddings-or-vector-databases-6c87733f6f47
- Intro – Building RAG Applications, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.youtube.com/watch?v=tW-TyXxyOUs
- Pre-Training vs Fine-Tuning vs RAG | by Piyali Das | Mar, 2026, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@piyalidas.it/pre-training-vs-fine-tuning-vs-rag-73c57d47b099
- RAG Security and Data Governance: Access Control for Retrieved Context – Scadea, เข้าถึงเมื่อ เมษายน 12, 2026 https://scadea.com/rag-security-and-data-governance-access-control-for-retrieved-context/
- RAG and Generative AI – Azure AI Search – Microsoft Learn, เข้าถึงเมื่อ เมษายน 12, 2026 https://learn.microsoft.com/en-us/azure/search/retrieval-augmented-generation-overview
- 8 Advanced RAG Techniques + How to Implement | by Pratik K Rupareliya | Medium, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@pratik-rupareliya/8-advanced-rag-techniques-how-to-implement-ac16caf4ebe7
- Advanced RAG Techniques for High-Performance LLM Applications – Neo4j, เข้าถึงเมื่อ เมษายน 12, 2026 https://neo4j.com/blog/genai/advanced-rag-techniques/
- Advanced RAG Retrieval (Reranking, Hierarchical, e… – Databricks Community – 104462, เข้าถึงเมื่อ เมษายน 12, 2026 https://community.databricks.com/t5/generative-ai/advanced-rag-retrieval-reranking-hierarchical-etc-in-databricks/td-p/104462
- Advanced RAG techniques: Querying & testing a RAG pipeline – Elasticsearch Labs, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.elastic.co/search-labs/blog/advanced-rag-techniques-part-2
- 9 Advanced RAG Techniques to Improve LLM Retrieval | Unstructured, เข้าถึงเมื่อ เมษายน 12, 2026 https://unstructured.io/blog/level-up-your-genai-apps-overview-of-advanced-rag-techniques
- You’re Building AI Wrong — RAG, Fine-Tuning, and the Architecture Decisions That Actually Matter, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@reliabledataengineering/youre-building-ai-wrong-rag-fine-tuning-and-the-architecture-decisions-that-actually-matter-3c7681fe077c
- RAG vs. Fine-Tuning: How to Choose – Oracle, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.oracle.com/artificial-intelligence/generative-ai/retrieval-augmented-generation-rag/rag-fine-tuning/
- RAG vs. Fine-Tuning in AI: A Comprehensive Comparison | by Burhan Khan – Medium, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@burhan-khan/rag-vs-fine-tuning-in-ai-a-comprehensive-comparison-34c57723582d
- RAG vs. Fine-tuning – IBM, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.ibm.com/think/topics/rag-vs-fine-tuning
- RAG vs. Fine-Tuning: Why Real-Time AI Outperforms Static Training – DataMotion, เข้าถึงเมื่อ เมษายน 12, 2026 https://datamotion.com/rag-vs-fine-tuning/
- RAG vs Large Context Window: Real Trade-offs for AI Apps – Redis, เข้าถึงเมื่อ เมษายน 12, 2026 https://redis.io/blog/rag-vs-large-context-window-ai-apps/
- What Is Flat-Rate Long-Context Pricing? How Anthropic Changed the Economics of RAG, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.mindstudio.ai/blog/flat-rate-long-context-pricing-anthropic-claude
- RAG vs long context model LLM – Elasticsearch Labs, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.elastic.co/search-labs/blog/rag-vs-long-context-model-llm
- Long-Context Models vs. RAG: When the 1M-Token Window Is the Wrong Tool – TianPan.co, เข้าถึงเมื่อ เมษายน 12, 2026 https://tianpan.co/blog/2026-04-09-long-context-vs-rag-production-decision-framework
- RAG Evaluation Metrics: Best Practices for Evaluating RAG Systems – Patronus AI, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.patronus.ai/llm-testing/rag-evaluation-metrics
- RAGAS | DeepEval by Confident AI – The LLM Evaluation Framework, เข้าถึงเมื่อ เมษายน 12, 2026 https://deepeval.com/docs/metrics-ragas
- RAG Evaluation Tools: Weights & Biases vs Ragas vs DeepEval – AIMultiple, เข้าถึงเมื่อ เมษายน 12, 2026 https://aimultiple.com/rag-evaluation-tools
- DeepEval vs Trulens – The LLM Evaluation Framework, เข้าถึงเมื่อ เมษายน 12, 2026 https://deepeval.com/blog/deepeval-vs-trulens
- Top 10 RAG & LLM Evaluation Tools You Don’t Want To Miss | by Zilliz – Medium, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@zilliz_learn/top-10-rag-llm-evaluation-tools-you-dont-want-to-miss-a0bfabe9ae19
- Metrics – Ragas, เข้าถึงเมื่อ เมษายน 12, 2026 https://docs.ragas.io/en/v0.1.21/concepts/metrics/
- RAG Evaluation Metrics Explained: Context Precision, Recall, Relevancy & Faithfulness, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.youtube.com/watch?v=wOoYP55eYF0
- RAG Evaluation Metrics: Assessing Answer Relevancy, Faithfulness, Contextual Relevancy, And More – Confident AI, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.confident-ai.com/blog/rag-evaluation-metrics-answer-relevancy-faithfulness-and-more
- Get better RAG responses with Ragas – Redis, เข้าถึงเมื่อ เมษายน 12, 2026 https://redis.io/blog/get-better-rag-responses-with-ragas/
- RAG Security and Privacy: Formalizing the Threat Model and Attack Surface – arXiv, เข้าถึงเมื่อ เมษายน 12, 2026 https://arxiv.org/html/2509.20324v1
- Securing your RAG application: A comprehensive guide – Pluralsight, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.pluralsight.com/resources/blog/ai-and-data/how-to-secure-rag-applications-AI
- Protect sensitive data in RAG applications with Amazon Bedrock | Artificial Intelligence, เข้าถึงเมื่อ เมษายน 12, 2026 https://aws.amazon.com/blogs/machine-learning/protect-sensitive-data-in-rag-applications-with-amazon-bedrock/
- Enterprise AI Cybersecurity: Protecting Sensitive Data in Retrieval-Augmented Generation (RAG) – Thales CPL, เข้าถึงเมื่อ เมษายน 12, 2026 https://cpl.thalesgroup.com/resources/data-security/secure-rag-data-protection-video
- LangChain vs LlamaIndex 2025: Complete RAG Framework Comparison – Latenode Blog, เข้าถึงเมื่อ เมษายน 12, 2026 https://latenode.com/blog/platform-comparisons-alternatives/automation-platform-comparisons/langchain-vs-llamaindex-2025-complete-rag-framework-comparison
- Llamaindex vs Langchain: What’s the difference? – IBM, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.ibm.com/think/topics/llamaindex-vs-langchain
- LlamaIndex vs LangChain: RAG framework differences – Statsig, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.statsig.com/perspectives/llamaindex-vs-langchain-rag
- LangChain vs LlamaIndex (2025) — Which One is Better? | by Pedro Azevedo – Medium, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/@pedroazevedo6/langgraph-vs-llamaindex-workflows-for-building-agents-the-final-no-bs-guide-2025-11445ef6fadc
- RAG Frameworks: LangChain vs LangGraph vs LlamaIndex – AIMultiple, เข้าถึงเมื่อ เมษายน 12, 2026 https://aimultiple.com/rag-frameworks
- 10 RAG examples and use cases from real companies – Evidently AI, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.evidentlyai.com/blog/rag-examples
- Business benefits of retrieval augmented generation – Hyland, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.hyland.com/en/resources/articles/rag-business-decisions
- Use cases for Retrieval Augmented Generation – AWS Prescriptive Guidance, เข้าถึงเมื่อ เมษายน 12, 2026 https://docs.aws.amazon.com/prescriptive-guidance/latest/retrieval-augmented-generation-options/rag-use-cases.html
- EPG จับมือ FIBO KMUTT ยกระดับองค์กรด้วย AI พัฒนาระบบ RAG เป็น AI บริหารจัดการองค์ความรู้ภายใน เพิ่มประสิทธิภาพ ลดต้นทุนองค์กร | Wealthy Thai | LINE TODAY, เข้าถึงเมื่อ เมษายน 12, 2026 https://today.line.me/th/v3/article/MLnYzZw
- Thai Sentence Embedding Benchmark – a Hugging Face Space by panuthept, เข้าถึงเมื่อ เมษายน 12, 2026 https://huggingface.co/spaces/panuthept/thai_sentence_embedding_benchmark
- Tested 14 embedding models on Thai — here’s how they rank : r/LocalLLaMA – Reddit, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.reddit.com/r/LocalLLaMA/comments/1rv3y4o/tested_14_embedding_models_on_thai_heres_how_they/
- OpenThaiGPT – GitHub, เข้าถึงเมื่อ เมษายน 12, 2026 https://github.com/OpenThaiGPT
- Enhancing large language models for Thai legal chatbots – Chula Digital Collections, เข้าถึงเมื่อ เมษายน 12, 2026 https://digital.car.chula.ac.th/cgi/viewcontent.cgi?article=75878&context=chulaetd
- OpenThaiGPT 1.5: A Thai-Centric Open Source Large Language Model – arXiv, เข้าถึงเมื่อ เมษายน 12, 2026 https://arxiv.org/html/2411.07238v1
- The Evolution of Retrieval-Augmented Generation (RAG) in AI – ResearchGate, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.researchgate.net/publication/399423892_The_Evolution_of_Retrieval-Augmented_Generation_RAG_in_AI
- RAG in 2026: Bridging Knowledge and Generative AI – Squirro, เข้าถึงเมื่อ เมษายน 12, 2026 https://squirro.com/squirro-blog/state-of-rag-genai
- 10 RAG Shifts Redefining Production AI in 2026 | by Ozgur Guler …, เข้าถึงเมื่อ เมษายน 12, 2026 https://medium.com/microsoftazure/10-rag-shifts-redefining-production-ai-in-2026-7acbdd66076c
- Trends in Active Retrieval Augmented Generation: 2026 and Beyond – Signity Solutions, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.signitysolutions.com/blog/trends-in-active-retrieval-augmented-generation
- Real-time RAG at enterprise scale – solved the context window bottleneck, but new challenges emerged – Reddit, เข้าถึงเมื่อ เมษายน 12, 2026 https://www.reddit.com/r/Rag/comments/1np5s9n/realtime_rag_at_enterprise_scale_solved_the/